
nginx 常用配置详解
环境为::CentOS 7。 nginx 版本: 1.21
配置文件入口
1 | /etc/nginx/nginx.conf |
这是入口文件,这个文件里有这样一句:
1 | include /etc/nginx/conf.d/*.conf; |
各个网站的配置文件是放在 conf.d 目录下的。这里面的所有 .conf 文件都会被读取。我们增加一个 test.conf。 yourname 就是你的用户名。在 /home/yourname/web/test/ 下面增加一个 index.html 文件 ,文件。文件内容为 hello。
1 | server{ |
启动 nginx,如果已经启动,reload 配置文件
1 | 启动 |
用 ip 或 localhost:3000 用浏览器访问网站,显示 hello。测试方法也可以用 curl localhost:3000,这样可能会更方便些。
文件类型
对于我们请求的内容,浏览器的处理方式是不一样的。浏览器如何判断内容,是根据 响应头 Content-Type 在入口配置文件 nginx.conf 中有这样两句:
1 | include /etc/nginx/mime.types; |
mine.types 是 Content-type 和文件后缀名的映射表。比如 xx.css 文件的 Content-type 是 text/css 。 default_type 是默认的 type。比如当访问 /a 的时候,如果 a 文件存在,nginx 会返回 a 文件,响应头 Content-type:application/octet-stream。 浏览器对application/octet-stream的处理方式是下载,而不是展示。
如果我们的请求地址是这样的 /a.html,/b.css, nginx 都可以自动处理。但有的时候,可能请求的地址是这样的 /a,这时就需要我们手动指定 type 类型。指定 type 类型很简单,有两种方法。
1 | location /css { |
自定义 log
打开 /etc/nginx/nginx.conf 找到 log_format
1 | log_format main '$remote_addr - $remote_user [$time_local] "$request" ' |
对于开发来说可以去掉 ua,ua 很长,去掉可以方便查看。尤其对于初学者,建议加上 $request_filename ,这个变量代表的是访问的实际文件路径,对于理解各种指令的效果,查找错误非常有帮助。
在入口的配置文件中用 Log_foramt 定义了一个 main。我们可以定义一个 dev,按你所需求选用需要的内容即可。 使用的时候,直接用 dev 这个名字就行。
1 | log_format dev '[$time_local] "$request" $request_filename' |
location 匹配规则
@ 匹配规则在后面的 try_files 中有举例
location 按如下优先级匹配
- = 绝对匹配,一个字符也不能差
- ^~ 前缀匹配
- ~(区分大小写), ~*(不区分大小写) 正则匹配
- 普通前缀匹配
2,4 的匹配是匹配最长优先。 3 的匹配是按顺序,写在前面的优先。
完全匹配
1 | location = /abc { |
location = abc 虽然只少了 / ,但这样是匹配不到的,一个字符也不能差。完全匹配优先级最高,无论写在前面还是后面。
^~ 前端缀匹配
1 | 正则匹配 |
^~ 匹配的优先级高于正则匹配。
初看到 ^~ 的人会误以为是正则匹配。这个要注意下,这个是前缀匹配,就是从前向后一个字符一个字符匹配。
1 | 普通前缀匹配 |
这两种写法的匹配方式是一样,^~ 的优先级更高。
正则匹配
1 | 普通前缀匹配 |
正则匹配的优先级高于普通前缀匹配。
1 | 正则匹配 |
正则匹配是按顺序来的,前面的匹配成功后面的就不再匹配了。
从性能上来说,尽量不要用正则,正则匹配性能最低。
前缀匹配最长优先
1 | location /abc { |
pass_proxy 代理
在前端代理主要是为了跨域。虽然前端跨域有多种方法,各有利弊,但用代理来跨域对开发是最友好的。用代理可以不用修改产品代码切换线上线下,非常安全。pass_proxy 默认会把 cookie 也一同转发。 常用的配置非常简单。
不带斜杠
前端 /api/user
后端 /api/user
1 | location ^~ /api/ { |
不带斜杠把 path 直接拼接在 url 后面;
带斜杠
前端 /api/user
后端 /user
1 | location ^~ /api/ { |
带斜杠会先去掉匹配到的 path, 再拼接。
正则匹配的时候不能带斜杠
~ 区分大小写正则匹配 ,~* 不区分大小写正则匹配 。location 用正则匹配的时候,proxy_pass 后面不能以 / 结尾,因为 nginx 不能处理这种情况。
1 | location ^~ /api/ { |
本例中,请求 localhost:3000/ 会导致 nginx 报错。
斜杠后面加路径
前端 /api/user
后端 /web/api/user
location ^~ /api/ { proxy_pass http://127.0.0.1:3001/web$request_uri; } 复制代码
代理之前 rewrite
1 | location /search/ { |
服务端获取真实 ip
反向代理: 简单来说 proxy_pass 把请求转发到其它服务地址的时候,就是反向代理。
如果是客户端与服务器直接连接,nginx 变量 $remote_addr 就可以拿到 真实ip。$remote_addr 是不能伪造的。但是如果 客户端是经过反向代理连接的服务器,服务器能拿到的只有代理服务器的 IP。为了能拿到客户端真实 IP,代理服务器在转发的时候需要加上一个 http 扩展头部 X-Forwarded-For。
所有代理的 ip 依次列出来,从远及近。
1 | X-Forwarded-For: IP0, IP1, IP2 |
X-Forwarded-For 是一个 HTTP 扩展头部。HTTP/1.1(RFC 2616)协议并没有对它的定义,它最开始是由 Squid 这个缓存代理软件引入,用来表示 HTTP 请求端真实 IP。如今它已经成为事实上的标准,被各大 HTTP 代 理、负载均衡等转发服务广泛使用,并被写入 RFC 7239(Forwarded HTTP Extension)标准之中。
1 | location /api/ { |
$proxy_add_x_forwarded_for变量包含客户端请求头中的”X-Forwarded-For”,与$remote_addr用逗号分开,如果没有”X-Forwarded-For” 请求头,则$proxy_add_x_forwarded_for等于$remote_addr。$remote_addr变量的值是客户端的 IP。
可能你会担心,ip 会不会被伪造。即使客户端伪造了 ip,nginx 也会用真实的 ip 进行重置。所以 $remote_addr 是可信的。
try_files
1 | try_files file ... uri; |
举两个例子,对应这两种语法。
1 | location /images/ { |
1 | location / { |
=404 的 等号 是必须的
try_file 后面必须有一个 file, 一个 url 或 code,file 可以有多个。
简单来说,try_file 按顺序检查 file,如果是文件夹,请在 file 后加 / ,如果 file 都不存在,根据最后一个参数做跳转。
借这个机会说一个 @ 在 location 中的用法。 @相当于命名了一个变量。
1 | location / { |
try_files 的一个应用场景就是单面应用.
1 | location / { |
如果请求的是 /a, 首先会查找 a 文件 是否存在,然后找 a 目录是否存在,如果都不存在,转到 /index.html。 再次命中 location / ,再次执行 try_files,这回找到 index.html 返回。
注意:如果 index.html 不存在,会报 500,所以用 try_files 的时候,要避免多次命中,最后的跳转最好转到别处。
1 | location / { |
这样修改后,只经历一次尝试,如果找不到,会报 404,不是 500。
error_page
1 | error_page code ... [=[response]] uri; |
error_page 会产生内部跳转
举例
1 | error_page 404 /404.html; |
如果找不到直接跳 404 页面没什么问题,但是如果是跳到首页,或是显示一张图片,
如果这样写
1 | error_page 404 /index.html |
当访问不存在的页面的时候,会跳到首页,但是状态码会显示 404。如果要显示 200,可以指定
1 | error_page 404 =200 /index.html |
页面缓存
http header 相关的缓存有两种
- 强制缓存
- 协商缓存
响应头部有两个值代表是否要强制缓存。Cache-Control 和 expires。至于为什么有两个头,expires 是历史遗留。
如果 不需要强制缓存 nginx 可以这样配置
1 | expires -1 |
nginx 发回的头部
1 | Cache-Control:no-cache |
Expires 的时间比当前早一秒。
也可以不配置 nginx。 默认是关闭强制缓存的 expires off
expires off 和 expires -1 都可以关闭强制缓存,但响应头不一样,expires off 不会发送 Cache-Control 和 expires。
如果需要强制缓存 这样配置
1 | expires 1d; |
1d 表示强制缓存一天。但是浏览器是否采用强制缓存还取决于浏览器的具体实现。
比如你在浏览器中直接请求一个图片地址(网络上随便找张图片就成),查看响应头,一般都会带有 expires 和 Cache-control ,下次请求应该会命中强制缓存,但是,下次请求的时候走的是协商缓存,状态码是 304。为什么会这样呢?因为 chrome 在直接请求图片的时候 在请求头中加上了 cache-control:max-age=0,表明本次请求不会采用强制缓存
当强制刷新的时候,值变为 no-cache,响应码 200。浏览器忽略强制缓存,服务端忽略协商缓存,重新返回内容。
1 | cache-control:no-cache |
不光是图片,chrome 直接访问 html 也不会命中强制缓存。对于浏览器的这个策略也是合理的。当访问一个网站的时候,我们第一个请求的是网站首页 index.html。如果首页被强制缓存了 10 天,那么可能 10 天内用户看到的都是旧内容。
cache-control:no-store 这个字段就是告诉浏览器不进行缓存。这个最彻底,无论是强制缓存还是协商缓存都会关闭。nginx 中这样配置
1 | add_header Cache-Control no-sotre; |
cache-control:no-cache 关闭强制缓存,但还是会走协商缓存。
关闭了强制缓存就会走协商缓存,Last-Modified、etag, nginx 都会默认加上。
给图片等静态资源加强缓存
1 | location ~* \.(?:css(\.map)?|js(\.map)?|gif|svg|jfif|ico|cur|heic|webp|tiff?|mp3|m4a|aac|ogg|midi?|wav|mp4|mov|webm|mpe?g|avi|ogv|flv|wmv)$ { |
一般会给静态资源设置一个较长的缓存。如果资源发生变化,会修改文件名。一般用 md5 值做为文件名。
root 与 alias
root 与 alias 决定到哪里在去访问实际的文件,区别在于 root 会拼接匹配到路径,alias 会替换匹配到的路径。我们看个实际的例子。
1 | location / { |
我们在用的时候,优先用 root。root 可以用在 http, server, location, if in location,alias 只能用在 location。root 对末尾的斜杠并不在意,兼容性更好。 alias 可以作为 root 的补充来使用。
url 美化
我们在开发的时候用的 url 是这样的
1 | /users?id=1 |
让别人访问的时候可能是这样的
1 | /users/1 |
所以我们需要把 /users/1 转为 /users?id=1 ,这时就需要 rewrite 出场了。
1 | location /users/{ |
当请求/users/1 的时候,命中 location /users/ ,执行 rewrite 指令, last flag 指示停止后面的 rewrite 指令并做内部跳转,匹配到 location /nodejs/ ,经过 proxy_pass 指令,转到 nodejs 服务。
你可能对 last 表示疑惑,都已经是最后了,怎么又跳到 /nodejs 了呢? 接下来,我详细讲解一下 nginx 的 rewrite 模块。为什么说一个模块呢?因为与 rewrite 相关的是一组指令。
nginx http rewrite module 详解
简单来说, ngx_http_rewrite_module module 用正则匹配请求,改写请求,然后做跳转,可以是内部跳转,也可以是外部跳转。
学习这个模块的时候 ,把 rewrite_log 打开,可以在 error log 里查看跳转信息
1 | rewrite_log on; |
注意 notice 是必须的
顺序执行和循环跳转
- 直接写在 server level 的 指令,顺序执行。
- 写在 location 中的指定顺序执行。可以跳到其它 location ,最多不超过 10 次。
server{ rewrite ^/users/(.)$ /show?user=$1 ; rewrite ^/teachers/(.)$ /show?teacher=$1 ; } 复制代码
请求 /users/1 ,先执行第一条 rewrite ^/users/(.)$ /show?user=$1 再执行第二条 rewrite ^/teachers/(.)$ /show?teacher=$1 ; 虽然第一条匹配到了,还是会执行第二条。这就是顺序执行的意思。
1 | location /{ |
请求 /users/1 命中第一个 location ,顺序执行第一个 rewrite,没命中,即使命中也会继续执行第二 rewrite ,命中。跳转到 第二个 location /show/,执行 rewirte 又回跳回 / ,这样循环 10 次,报 500 错误,查看 error 日志可以看到说明。
1 | rewrite or internal redirection cycle while processing "/show/1" |
这个过程演示了 location 中 rewrite 的执行逻辑。顺序执行,循环跳转。
rewrite module 中还有 5 个指令 break, if, return, rewrite, and set。 return 可以直接返回,打断后面的 rewrite module 指令的执行。
1 | location / { |
执行 return 后,后面的指令就没有机会执行了。 set,break 比较简单,和其它语言差不多。下面着重讲下 rewirte 指令的 flag。
rewrite regex replacement [flag]
flag 有四种
- last .停止执行后面的 ngx_http_rewrite_module 指令,并发起新的 location 匹配。
- break. 停止执行后面的 ngx_http_rewrite_module 指令。然后没有后续了,不再发起 location 匹配。
- redirect 执行 302 跳转,后面的指令不再执行。
- permanent 执行 301 跳转,后面的指令不再执行。
last、break 停止执行的是 ngx_http_rewrite_module 指令,其它指令不受影响,还是会执行的。
regex 匹配的是路径部分
1 | location / { |
如果 replacement 是 http 开头,是可以直接跳转的
1 | location / { |
最后再讲下 if ,if 语句不复杂,但是非常有用,可以这样说,用 if 可以实现很多指令,但是用内置指令更简洁,还是要优先用指令。
if ($param) 如果 $param 为空字符串或 0 为假,其它情况为真。
注意 if 后面必须要有空格,否则报错。
1 | set $param '0'; |
用 = ,!=判断相等。
1 | if ($request_method = POST){ |
注意 是一个 = 不是两个=, 等号左右必须要有空格,否则报错
用正则表达式判断
1 | ~ 区分大小写 |
用 flag
1 | -f !-f 文件是否存在 |
return
1 | return code [text]; |
1 | location /admin/{ |
移动 pc 适配
我们希望在访问 一个网址的时候,如果是在 pc 端打开的时候,显示 pc 的页面,如果是在移动端打开的,显示移动端的页面。网址只有一个
1 | server{ |
这个设置需要放在 server 下面,对于所有 location 有效。在 location 里如果有需要还可以修改 root,所以 set 一个 $isMobile 的变量,方便后面使用。
ipad 虽然是移动设置,但从尺寸上来看更接近 pc,所以页面在 ipad 打开,一般会显示 pc 的页面
配置 https 服务
虽然在开发的时候用 http 就行,但有的时候,必须要 https 才行。所以配置开发环境可能也得配置 https 服务。我们的目的是为了让服务跑起来,还是很简单的。
- 申请证书
- 证书包含一个 crt 文件一个 key 文件,crt 为证书,key 为密钥
- 配置 nginx
如果你正在做一个项目,这个项目的域名证书应该是提前就申请好的。用这个证书就行。本地配 host ,配项目的线上域名,就可以测试了。
1 | server { |
配置 https 服务,只需要三步
- 监听 443 端口
- 设置证书的绝对路径
- 设置密钥的绝对路径
只这三步就完成,很简单吧。
要启用 http2 也很简单, 只需要在 listen 后面加 http2 即可。
1 | listen 443 ssl http2; |
请求地址末尾加斜杠与不加斜杠
请求 juejin.cn/b 与 juejin.cn/b/ 有什么区别吗? nginx 解析起来区别就大了。
不加斜杠,如果存在 b 文件,返回 文件 b 如果不存在文件 b,但有文件夹 b, 301 到 b/,在浏览器中看到的现象是发了两个请求.如果 b 下面没有 index.html,返回 403,如果有,返回内容。

如果没有 index.html,为什么是返回 403 而不是 404 呢?
这是因为 nginx 如果找不到 index.html,会尝试浏览目录,默认是不允许的。autoindex off;
如果既没有文件夹 b 也没有文件 b 返回 404
为什么访问 b/ 会去查找 b/index.html,这是因为 index 指令默认是这样的 index index.html
nginx 默默做了这么多,就是为了让我们用起来方便。如果从性能方面来考虑,写完整地址最好,别让 nginx 去猜了。用户怎么输入网址我们管不了,但是我们在写跳转地址的时候,最好是写完整地址。
请求头信息对应的 nginx 变量
nginx 中的有些变量有是规律,按规律可以方便记忆。

对每一个请求标头,都对应一个变量
大小写不敏感,以 http* 开头, - 改为 * 。
- $http_accept
- $http_cache_control
cookie 的中的变量
比如 cookie 中 包含 name=jack,用 $cookie_name 可以拿到 jack 这个值。
- cookie_name
arg 中的变量
比如有这样的 get 请求 index.html?name=jack ,用 $arg_name 可以拿到 jack 这个值。
- arg_name
nginx 接收客户端提交
当我们提交一个表单的时候,会生成一个请求的 header,body。在 header 中 Content-Length:123 标明 content 字节大小。nginx 接收到 header,先检查 header 大小,如果 header 大小超过 client_header_buffer_size 的默认值 1K,并超过 large_client_header_buffers 的默认值 8K nginx 会报错。
检查 Content-Length ,如果超过 client_body_buffer_size 默认值 8K(除了 x86 的 64 位系统是 16K),内存缓冲区无法接收,会存到 client_body_temp_path 指定的目录。但是接收的 body 总大小不是无限的,不能超过 client_max_body_size 的默认值 1M。
对于大多数请求来讲,都是 get 请求,我们可以直接躺平,默认值即可。 get 请求没有 body,超限的情况可能是 cookie 过多,url 过长。一般来说,超出的可能性不大。
对于 post 请求,当上传文件的时候,可能会超限。nginx 默认只能接收 1M 的内容,可以增加这个默认值。
1 | locatoin /upfile/ { |
如果网络状态不好,可能刚发一个字节,就断了,如果在默认 60 秒内没有再次发送,nginx 会中断链接。这样做是为了节省服务器资源。可以通过 修改 client_body_timeout 和client_header_timeout 改变默认值。
1 | server{ |
60 秒有点太保守了,可以减小这个值。
nginx gzip 压缩
gzip 压缩的知识还是非常多的,不过只是启用 gzip ,打开功能,还是很简单的。
1 | server{ |
gzip 指令默认是 off,设置为 on 打开 gzip。如果只设置 gzip on gzip 可有不会生效,gzip 默认只对大于 20 字节的内容做处理。我们在测试的时候页面内容都很少,很容易少于 20 字节gzip_min_length,设为 0 代表所有大小都压缩。
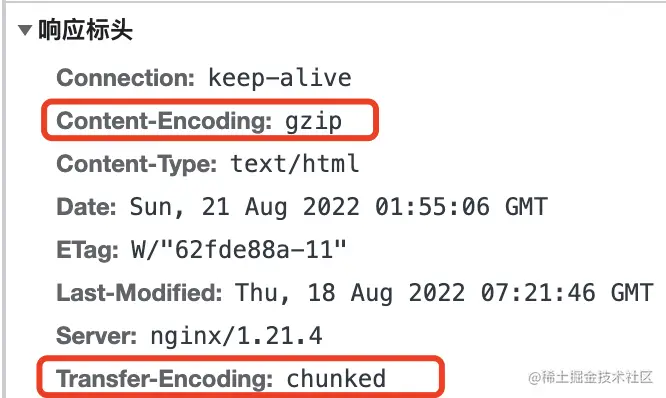
启用压缩后,在请求 /index.html 响应 200 的时候,查看 header,发现有两个增加,并且 Content-Length 不见了。
Content-Encoding:gzip 内容的格式为 gzip,告诉浏览器,需要 gzip 解压再展示。
Transfer-Encoding:chunked 数据是通过一系列块来传输的,省略 Content-Length ,为了得到内容大小,需要把每个 chunk 的大小 加起来。
为什么打开 gzip 后 content-length 信息没有了呢? 这是因为 nginx 的压缩是异步的,发送头的时候,nginx 可能正在压缩,不知道压缩完成的文件大小。
指定需要 gzip 的文件
我们访问 /index.css ,发现并没有压缩,这是因为 gzip ,默认只压缩 text/html 类型的文件。
增加 text/css 类型后,css 文件 也可以压缩了。
1 | gzip_types text/html,text/css; |
压缩级别。
gzip 有 9 个压缩级别,越高,压缩效果越好,但是对 cpu 的消耗越多。默认压缩级别为 1 。我们可以设置一个合适的级别,比如 2;
1 | gzip_comp_level 2; |
gzip_static
前面讲的 nginx 处理 gzip 的方式是 服务器负责压缩,这样会消耗掉很多 cpu 资源。我们可以先把文件压缩成 gzip,nginx 直接拿 gzip 过的文件就行了。预处理的好处不光是节省了 cpu 压缩时间,还可以 让 nginx 可以用 使用 sendfile 系统调用来传输文件,性能得到提高。
新版本的 nginx 已经 默认安装了这个模块,如果是老版的 nginx 这个模块需要安装一下。
1 | gzip_static always; |
如果加上这句,nginx 不报错,说明 gzip_static 模块已经安装了。
gzip_static 可以有三个值。
- off 默认值。 不启用 gzip_static。gzip 功能还是可以用的。
- on 启用。 当客户端支持 gzip 的时候,发送压缩文件,不支持的时候发送原文件。
- always 总是。 不管客户端是否支持,都优先发送压缩文件。如果没有压缩文件,再发送原文件。
实操的时候,用 always 比较好。现在不支持 gzip 的浏览器太少了,这样可以免掉 nginx 判断的步骤,对性能有所提高。为了方便 nginx 查找(文件越多,查找越慢),只保留 gzip 文件,原文件全部删除。
负载均衡
1 | upstream servers { |
nginx 常用的负载均衡 是 upstream 来完成的。默认采用轮询的方式依次访问各个服务器。可以给每个服务器加权重,调整访问的频率,权重越高,被访问的越频繁。
1 | upstream servers { |
根据 ip 也可以分配请求。这样能保证同一个用户可以由同一个服务器来服务,可以解决登录 session 的问题。但是根据 ip 分配 可能导致某些服务器请求过多,又不能再做调整。所以解决 登录 session 的问题,可以用统一的 redis 服务来解决。
1 | upstream servers { |
根据 url 分配 请求。比如这样的场景, 资源(图片等静态文件)服务器从源服务器拉取资源后,下次请求会再次落到这个资源服务器,就可以直接返回结果 ,不用再从源服务器请求资源了。
1 | upstream servers { |
最后再介绍一下最小连接数方案。在这种场景下,least_conn 算法很简单,首选遍历后端集群,比较每个后端的 conns/weight(连接数除权重),选取该值最小的后端。 如果有多个后端的 conns/weight 值同为最小的,那么对它们采用加权轮询算法。
1 |
|






